阿里巴巴云原生混部系统 Koordinator 正式开源

 分类:
分类: 已被围观
已被围观 作者 | 逐灵
业界很多互联网公司或多或少都有布局将不同特征类型工作负载协同调度的技术方向,充分利用负载之间的消峰填谷效应,让工作负载以更稳定、更高效、更低成本的方式去使用资源。这样的一套系统或机制,也就是业界时常提及的 “混部”概念。
阿里巴巴在 2011 年开始探索容器技术,并在 2016 年启动混部技术研发,至今经过了多伦技术架构升级,最终演进到今天的云原生混部系统架构,实现了全业务规模超千万核的云原生混部,混部天平均 CPU 利用率超 50%,帮助阿里巴巴节省了大量的资源成本。
混部是在互联网企业内部重金打造的成本控制内核,凝聚了众多的业务抽象和资源管理的思考优化经验,因此混部通常都需要数年的打磨实践才能逐渐稳定并产生生产价值。是不是每家企业都需要很高的门槛才能使用混部,都需要大量的投入才能产生价值?那让我们的Koordinator来尝试给出回答。
Koordinator 正是基于内部超大规模混部生产实践经验而来,旨在为用户打造云原生场景下接入成本最低、混部效率最佳的解决方案,帮助用户企业实现云原生后持续的红利释放。
Koordinator: 取自 coordinator,K for Kubernetes,发音相同。语意上契合项目要解决的问题,即协调编排 kubernetes 集群中不同类型的工作负载,使得他们以最优的布局、最佳的姿态在一个集群、一个节点上运行。
谷歌内部有一个调度系统名叫 Borg,是最早做容器混部的系统,在其论文公开发表之前在行业上一直是非常神秘的存在。云原生容器调度编排系统 Kubernetes 正是受 Borg 设计思想启发,由 Borg 系统的设计者结合云时代应用编排的需求重新设计而来。Kubernetes 良好的扩展性使其能适应多样的工作负载,帮助用户很好的解决工作负载日常运维效率。
Koordinator 是完全基于 Kubernetes 标准能力扩展而来,致力于解决多样工作负载混部在一个集群、节点场景下的调度、运行时性能以及稳定性挑战。项目包含了混合工作负载编排的一套完整解决方案,包括精细化资源调度、任务调度、差异化 SLO 三大块。通过这样一套解决方案实现:
帮助企业用户更多工作负载接入 kubernetes,特别是大数据、任务处理相关的工作负载,提高其运行效率和稳定性
通过开源技术标准,帮助企业用户在云上、云下实现一致的技术架构,提升运维效率
帮助企业用户合理利用云资源,在云上实现可持续发展
混部需要一套完整、自闭环的调度回路,但在企业应用混部的过程中,将要面临的两大挑战是:
- 应用如何接入到混部平台
- 应用如何在平台上能够运行稳定、高效
Koordinator 吸取了阿里巴巴内部多年的生产实践经验教训,针对这两大挑战针对性的设计了解决方案,旨在帮助企业真正意义上的用上混部,用好 Kubernetes,而不是秀技术秀肌肉。
Koordinator 1.0 的整体架构如下图所示,为了用户提供了完整的混部工作负载编排、混部资源调度、混部资源隔离及性能调优解决方案,帮助用户提高延迟敏感服务的运行性能,挖掘空闲节点资源并分配给真正有需要的计算任务,从而提高全局的资源利用效率。
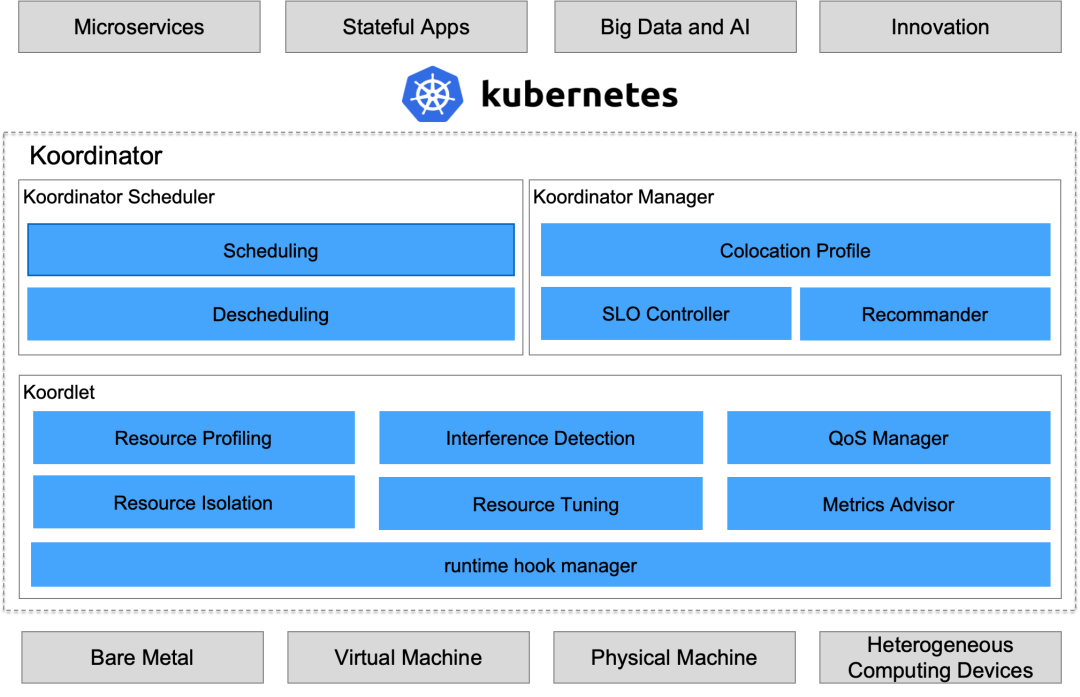
1.超大规模生产实践经验锤炼
2021 双 11 之后阿里对外宣布了“首次!统一调度系统规模化落地,全面支撑阿里巴巴双 11 全业务”:
作为阿里巴巴的核心项目,阿里云(容器团队和大数据团队)联合阿里巴巴资源效能团队、蚂蚁容器编排团队,历时一年多研发和技术攻坚,实现了从“混部技术”到今天“统一调度技术”的全面升级。
今天,统一调度已实现阿里巴巴电商、搜推广、MaxCompute 大数据的调度全面统一,实现了 pod 调度和 task 高性能调度的统一,实现了完整的资源视图统一和调度协同,实现了多种复杂业务形态的混部和利用率提升,全面支撑了全球数十个数据中心、数百万容器、数千万核的大规模资源调度。
作为云原生混部的践行者,阿里巴巴是真刀真枪的在生产环境中推进混部技术理念,并在去年双 11 完成了超过千万核的混部规模,通过混部技术帮助阿里巴巴双 11 节约超过 50% 的大促资源成本,在大促快上快下链路上提速 100%,助力大促实现丝滑的用户体验。
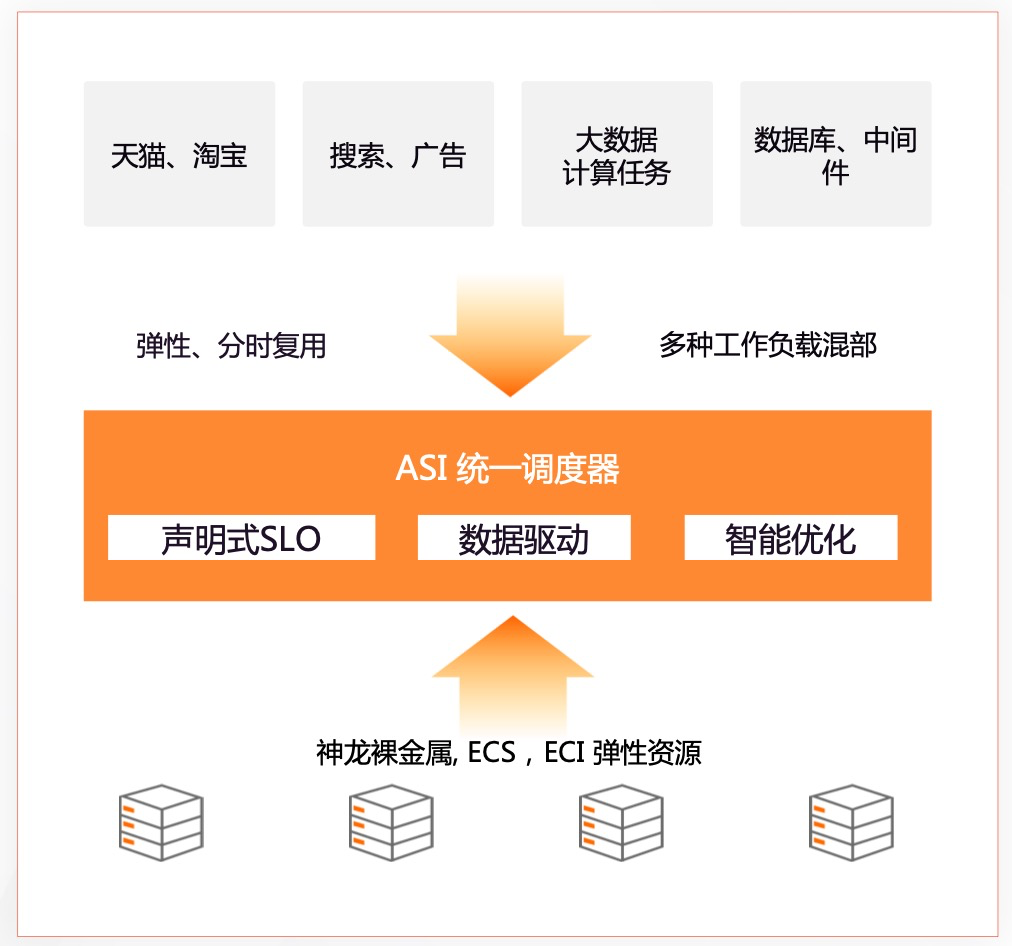
回头去看,阿里巴巴坚定的推进混部技术,主要是考虑到以下方面带来的问题:
- 利用率不均衡:在非混部时代,几大资源池之间的资源利用率不均衡,大数据资源池利用率极高长期缺乏算力,而电商资源池日常利用率比较低,空闲了大量的计算资源,但出于灾备设计又不能直接下掉机器提高在线密度。混部的初衷是让全局资源调度更合理,在日常态通过混部将大数据的任务调度到电商资源池中,充分利用这部分空闲的资源。
- 大促备战效率低:在大促时为了减少大促资源采购,希望在大促时能够借用大数据资源池,部署电商任务支撑流量洪峰同时。在非混部时代,这样的弹性资源借用只能通过腾挪机器的方式推进,大促支持的效率较低很难大规模实施。
正是在双 11 这样的峰值场景驱动之下,阿里的混部调度技术持续演进,积累了大量的生产实践经验,到今天已经是第三代即云原生全业务混部系统。这样一套基于云原生理念的混部技术解决方案,脱胎于阿里巴巴,希望通过开源社区辐射到整个行业,帮助企业在云原生容器调度方向上加速快跑。
2.聚焦混部技术,支持丰富的场景
混部是一套针对延迟敏感服务的精细化编排+大数据计算工作负载混合部署的资源调度解决方案,核心技术在于:
- 精细的资源编排,以满足性能及长尾时延的要求,关键点是精细化的资源调度编排策略及 QoS 感知策略
- 智能的资源超卖,以更低成本满足计算任务对计算资源的需求,并保证计算效率的同时不影响延迟敏感服务的响应时间
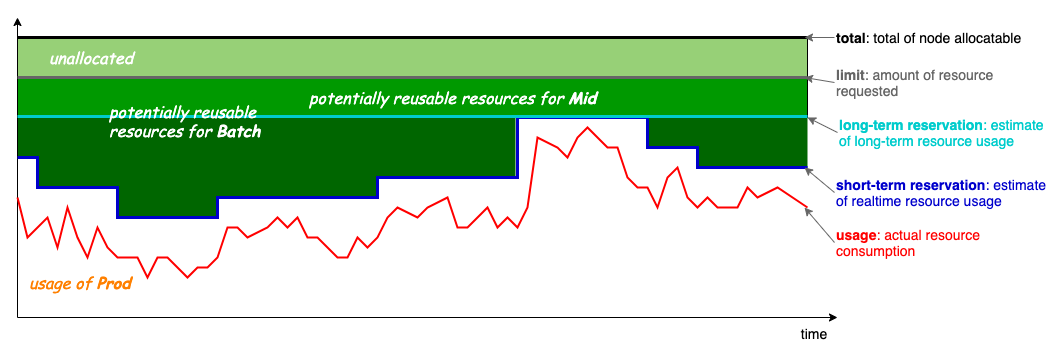
上图是 Koordinator 混部资源超卖模型,也是混部最关键最核心的地方。其中超卖的基本思想是去利用那些已分配但未使用的资源来运行低优先级的任务,如图所示的四条线分别是:
- limit: 灰色,高优先级 Pod 申请的资源量,对应 kubernetes 的 Pod request
- usage: 红色,Pod 实际使用的资源量,横轴是时间线,红线也就是 Pod 负载随时间的波动曲线
- short-term reservation: 深蓝色,是基于 usage 过去一段时间(较短)的资源使用情况,对其未来一段时间的资源使用情况的预估,reservation 与 limit 之间也就是已分配未使用(预估未来一段时间也不会使用)的资源,可以用于运行短生命周期批处理任务
- long-term reservation: 浅蓝色,类似于 short-term reservation 但预估使用的历史周期较长,从 reservation 到 limit 之间的资源可用于较长生命周期的任务,其可用资源相比 short-term 更少但稳定性更高
这一套资源模型支撑了阿里巴巴内部全业务的混部,足够精炼的同时也具备很强的灵活性。Koordinator 整个混部资源调度的大厦构建在这样一个资源模型的基础之上,配合上优先级抢占、负载感知、干扰识别和 QoS 保障技术,构建出混部资源调度底层核心系统。Koordinator 社区将围绕这个思路投入建设,持续将混部场景的调度能力展开,将阿里巴巴内部丰富场景支持的经验输出到社区,解决企业面临的真实业务场景问题。
3.双零倾入,超低接入成本
企业接入混部最大的挑战是如何让应用跑在混部平台之上,这第一步的门槛往往是最大的拦路虎。Koordinator 针对这一问题,结合内部生产实践经验,设计了“双零侵入”的混部调度系统。
第一个零倾入,是指对 Kubernetes 平台的零倾入。行业内的人大多知道,将 Kubernetes 应用于企业内部的复杂场景混部时,因为这样或者那样的原因总是需要对 Kubernetes 做一定量的修改,特别是节点管理(Kubelet)部分,这部分修改本身具备较大的技术门槛,同时也为给后续的 Kubernetes 版本升级带来巨大的挑战。企业为了解决这一问题,往往需要专门的团队来维护这一些定制化的修改,并且具备很大的沉默成本,等到线上出现问题或者需要升级新版本时,熟悉这份修改的同学可能已不知去向。这给企业带来了很大的技术风险,往往让混部技术的推广受阻。而 Koordinator 混部系统,设计之处即保证了不需要对社区原生 Kubernetes 做任何修改,只需要一键安装 Koordinator 组件到集群中,不需要做任何配置,既可以为 Kubernetes 集群带来混部的能力。同时,在用户不启用混部能力时,不会对原有的 Kubernetes 集群有任何形式的打扰。
第二个零倾入,是指对工作负载编排系统的零倾入。想像一下,在企业内部的 Kubernetes 集群之上提供混部能力之后,将面临的问题是如何将企业的工作负载接入进来,以混部的方式运行。一般情况下将会面临的两种情况是:
- 工作负载具备企业私有运维特性,由平台或运维团队的系统管理这些工作负载的日常升级发布、扩容缩容,而企业推进混部的容器或 SRE 团队与平台运维团队之间,存在着组织的鸿沟(或大或小),如何推动平台团队改造工作负载管理机制,对接混部的协议,也是一个不小的挑战。
- 工作负载以原生的 Deployment/StatefulSet/Job 的方式管理,对其 Kubernetes 内部的设计实现或改造成本超出了团队的预期,也将成为推行混部的挑战。
Koordinator 针对应用接入层的改造成本,设计了单独的工作负载接入层(Colocation Profile),帮助用户解决工作负载接入混部的难题,用户只需要管理混部的配置(YAML)即可灵活的调度编排哪些任务以混部的方式运行在集群中,非常的简单且灵活。当前 Koordinator 为用户提供了混跑 Spark 任务的样例,未来,社区将持续丰富工作负载接入层的特性,支持更多场景的零倾入接入。
4.云上、云下一致的用户体验
Koordinator 开源项目是阿里巴巴云原生 2.0 的重点战役,用户除在自己的环境中可以体验到 Koordinator 混部带来的技术红利,也可以将其部署到任意一个云厂商中,保持混合云、多云的架构一致。当然,也可以在阿里巴巴提供的多款云产品中获得一致的用户体验,一次设计对接多处发挥价值。

可以看到,除了支持内部超大规模的业务混部外,Koordinator 也是阿里云容器服务集成的解决方案,社区将持续的保持活力,致力于将混部变成平民化、通用化、标准化的技术能力。
最早做容器混部的是 Borg, 在 Google 内部运行超过 15 年,最新公开的资料是 Borg: the next Generation[1]。国内互联网公司内部推进混部接近 10 年,其中阿里巴巴的混部技术也经历过了 3 代技术架构升级变迁,最终走到全局混部的终极形态。混部帮助阿里巴巴的电商、搜索、大数据业务极大的提高了大促的备战效率,也为历年的双 11 大促节省了大量的计算资源。
我们坚信,云原生混部是企业容器调度技术发展的必然方向,只有通过工作负载的混合编排,才能在业务多可用区灾备架构下实现更好的资源利用效率,才能充分的发挥不同类型负载的消峰填谷效应,从而完全的发挥出计算资源潜力,最大化释放云计算的价值。
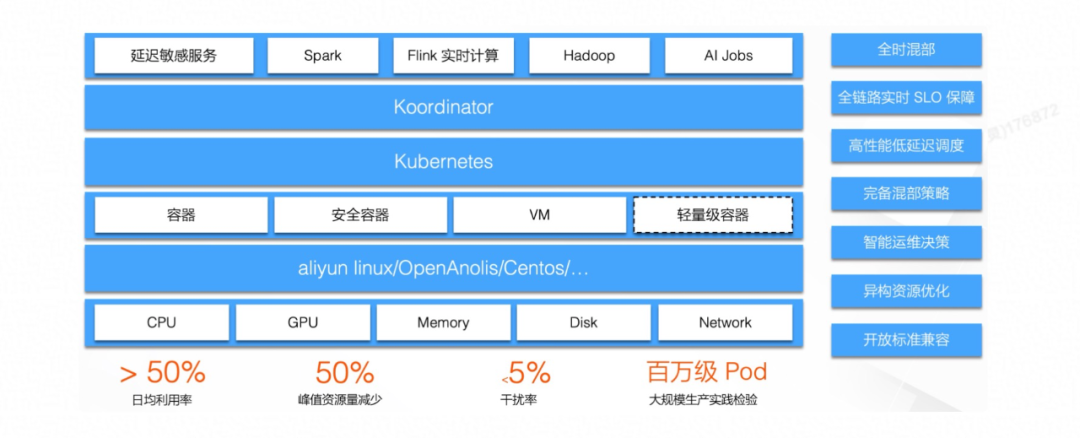
Koordinator 的开源,希望让更多的企业能够看见并用上云原生混部的能力,帮助企业加速云原生化的过程。在技术上,Koordinator 能够帮助企业实现更多的负载能够接入到 Kubernetes 平台,丰富容器调度的工作负载类型,继而发挥出工作负载错峰分时的特征,从而实现效率、成本上的收益,保持长期可持续发展的健康形态。
当前,Koordinator 已经支持了 Spark 任务场景的混部,同时也提供了低成本接入混部的解决方案,期待看到你的混部应用案例,听到你的反馈!未来,Koordinator 社区将持续的丰富混部的场景及业务形态,支持 Flink、Hadoop、AI Jobs、音视屏任务等,尽情期待。
参考链接[1]:https://research.google/pubs/pub49065/
可优惠产品清单

一次合作 终生朋友

部分客户(无排名)









