网络攻击强大,微软中招!企业风控的五大反思!

 分类:
分类: 已被围观
已被围观
 编辑搜图
编辑搜图
3月22日,360政企安全对外披露了美国国安局(NSA)针对中国境内目标采用的Quantum网络攻击平台的技术特点,并证明了其无差别化网络攻击,不但能够劫持世界任何角落的页面流量,而且可以实施零日(0 day)漏洞利用攻击,并远程植入后门程序。
隔天24日,网上曝出微软被黑客组织Lapsus$盗用了的一个账户,并获得了有限访问权限,并声称掌握部分源代码。
即便是微软这样的巨头,也不可避免的中招了!
对此次入侵,微软表示,“我们的网络安全响应团队迅速参与修复受损帐户,并防止黑客组织进一步活动。”
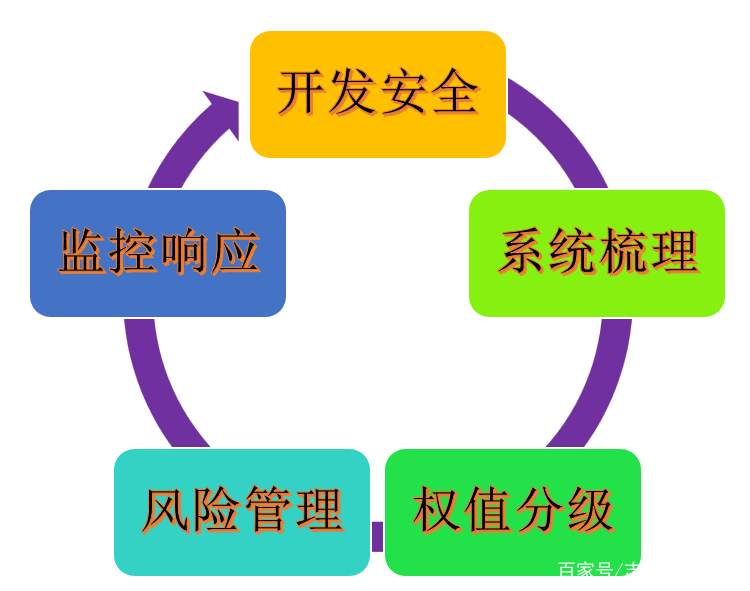
不到三天接料爆料出重大的安全新闻,相信国内各个企业的风控部门都会倒吸一口凉气。有的已经开始组织安全人员,准备撸起袖子开展自身系统安全的检查与整改工作。不过,常言道“磨刀不误砍柴工”。我们与其在现有的生产环境中大海捞针,不如先静下心来,从系统开发与运营两个维度出发去思考。我这里结合以往的从业经历,总结除了五大系统安全实践参考要点:开发安全、系统梳理、权值分级、风险管理、监控响应。希望能帮助各位快速锁定安全隐患,防患于未然。
 编辑搜图
编辑搜图
开发安全
相信大家对 DevSecOps一词并不陌生,它由敏捷开发模式演变而来,旨在将安全性尽量“左移”到各个开发子周期的初始阶段,以协助研发人员尽早获悉应用代码中可能存在的威胁与漏洞。对此,我们可以采用如下四种实践模式:
未雨绸缪式:分割应用程序之间依赖性,以便隔离各个组件,将来漏洞和威胁限制在单个组件中,进而保证其他组件的持续运行。该模式的典型场景是微服务应用。
一票否定式:通过代码逻辑和用户场景的构建,在有恶意行为出现时,中断其所有进程。例如:如果有用户在访问某个网站时,试图进行跨站脚本注入攻击,那么其任何操作行为及其会话就应当被直接阻止。
他山之石式:在缺乏安全专家的团队中,可以通过业界常用的威胁模型与管控模型,来提前识别应用组件可能面临的潜在风险,并选取最佳防护措施。
川流不息式:利用自动化监控手段和获取的多种输入参数,将对于运行环境与用例的风险评估,集成到软件服务整个生命周期中。
此外,在软件应用的构建中,我们也需要落实如下方面:
针对不同的应用服务,设置不同的用户职能组别。
通过加密等方式,避免在应用数据的传输过程中,泄漏任何密码、口令、证书或私钥信息。
将多种应用程序的登录方式统一为多因素认证(MFA)+单点登录(SSO),以实现用户账号权限的自动匹配。
使用成熟的产品来管理密钥,及时发现过期与注销证书等情况。
检查程序代码,及时发现无效或过时的依赖项、代码库、潜在的内存泄漏、死循环、以及代码漏洞。
系统梳理
当然,除了提供软件应用服务,我们也离不开承载着应用的系统架构。随着企业的发展,其IT架构与平台会呈现错综复杂的结构状态。因此,我们需要通过钻机房,登设备,查线路,测应用,跟业务,访用户等活动,梳理出日常IT服务所处的环境,以及所用到的资源。
在清点并填写具体内容之前,我们需要事先做好条目的分类与定义,以保证生成的清单具有统一性和规范性。而在实践中,我们需要以数据的特征与状态为依据,去发现那些存储着静态数据的有形硬件设备,处理着实时数据的软件应用,承载着动态数据的网络,包含着结构化数据的数据库,存放着非结构化数据的云平台,以及被用于持续读写数据的文件服务器与用户终端。
为了保证准确性,我们可以采用“自动化工具发现 + 人工录入 + 二次审核”的方式,构建出全面、完整、直观的系统基线。这将是我们后期进行整改的参考标准。
权值分级
完成了系统的梳理,我们便可以从信息安全的经典理论出发,全面考虑各种组件与数据在其机密性(C)、完整性(I)和可用性(A)受到破坏时,可能给企业带来的影响程度,并据此赋予三个维度相应的数值。有了赋值,我们便可以基于如下的公式,计算出资产的权重值(V):
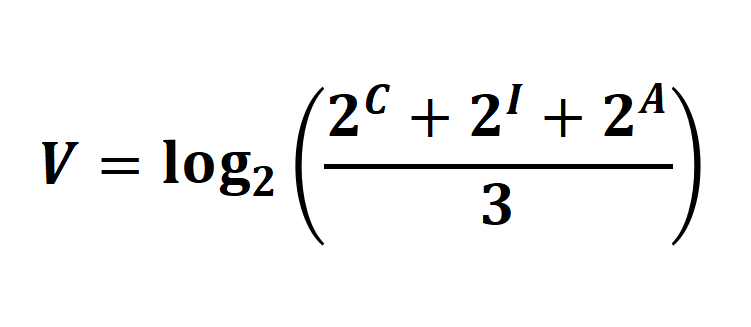 编辑搜图
编辑搜图
值得注意的是,我们不但可以给软硬件资产赋值,也可以对数据分配权重值,以进步厘清有哪些数据需要被加密存放,哪些数据在使用需要立即清除,哪些数据仅能在内部被受限制地使用,以及哪些数据可以被直接对外开放。当然,精确的数字往往不便于界定,我们可以通过取值范围来划分出:“绝密、机密、隐私、敏感 、公开”等级。
同时,在一些机密性要求极其严格的场合,我们甚至需要对某些结构化数据表中的字段,非结构化数据域中的键/值(K/V),以及某个介质对应的属性标签里的元信息,进行不同安全级别的区分。当然,除了对数据予以逻辑分级,我们也需要以物理标签的形式,来显著标识设备部件的密级。
风险管控:运营风险识别及应对
一些开发者或许会疑惑:有哪些影响C、I、A的因素呢?此时我们就需要来识别运营环境中针对组件与数据的外部威胁、内部弱点、以及组合到一起形成的风险了。通常,我们可以采取如下四步来识别风险:
1、收集与识别:根据过往的记录、以及业界经验,招集不同角色的人员,使用头脑风暴、问卷访谈、矩阵图表等方法,识别现有环境中的隐患。例如:
(1)技术层面上:软、硬件介质的故障与损坏、应用系统的自身缺陷、恶意软件的死锁、以及网络上的各种拒绝服务的攻击等。
(2)支撑系统层面上 :机房停电、漏水、以及运营商网络中断等。
(3)人为层面上:访问挂马的网站、各种操作性的失误、以及文件数据被误改或篡改等。
(4)管理层面上:人员意识的缺乏、处置方式的错误、以及规章制度的不完善等。
2、分析与评估:运用定性/定量等不同的方法,对已发现的风险从程度、范围、以及可能性三个维度进行评估与排序,进而得出风险等级矩阵。在实际中,我们可以参考如下的界定标准进行风险的量化:
(1)损害的程度 – 轻微、一般、较大、严重、特大等。
(2)影响的范围 - 整个企业、所有外部客户、多个分站点、某个部门、部分系统、单个服务等。
(3)发生的可能性 – 可考虑物理与逻辑上所处的区域、自身的容错能力、等级保护与合规的达标情况等。
3、应对与处置:我们需要根据本企业的风险偏好(即风险接受程度),在通用的风险减轻、转移、规避、以及接受等处置方法中进行选择,并予以应对。其中,我们需要对如下两个方面引起重视:
(1)根据木桶原理,我们应当注意处置措施的一致性,以免出现局部“短板”。
(2)在分清风险的所有者、以及控制实施者的基础上,兼顾时间、预算等成本,灵活调整各项管控策略。
监控响应:最小化安全事件
目前,许多企业都通过建立主动监控和响应机制,来最小化安全事件对于业务运营的负面影响。例如,运营团队可以设置可靠性工程师(SRE)岗位,在日常预防性例检中,实时地监控关键设备的状态,及时根据文档发现并定位部件故障。同时,他们也可以通过部署诸如Zabbix等开源的日志与事件监控工具,以远程和集中的方式,审查并跟踪各项性能指标。
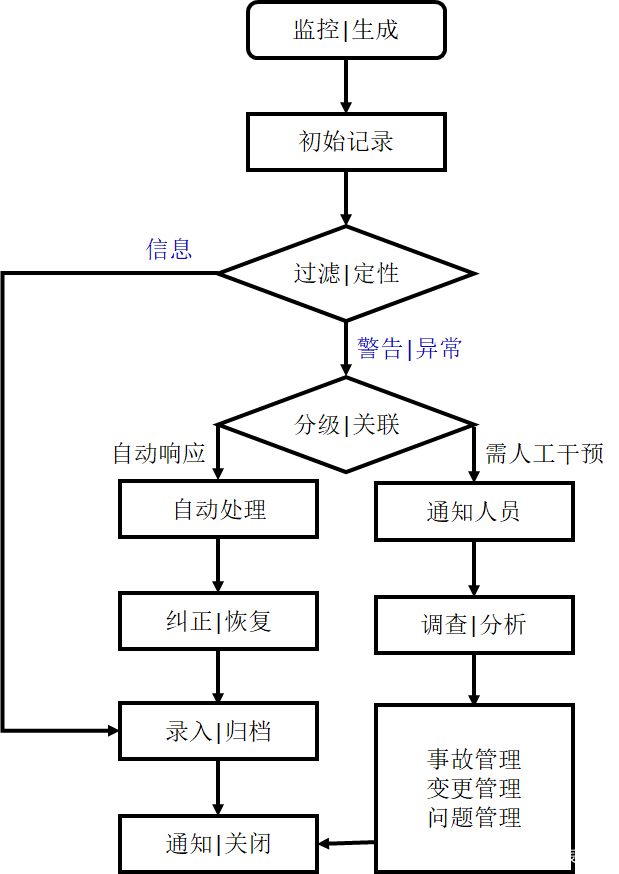
下面,我以某个云端业务环境为例,来讨论如何在事件监控与响应的整个生命周期中,实施管理和控制。
检测与识别阶段:分别抓取和过滤来自各个虚拟机的系统事件、以及基于网络的异常流量信息,然后持续将经过筛选的日志信息写入HBase数据库,为后期的各种关联分析、以及必要的取证提供重要依据。
调查与分析阶段:运用工具按照特征代码,对事件的种类予以分组、对事件的发生频率进行统计。同时,我们可以引入应用性能分析(APM)模块,精确地定位是在应用服务的哪个URL处出现了访问速度的骤降,或是用户在提交哪个SQL语句时出现了延时,以便更快地定位根本问题。
抑制与补救阶段:可以通过暂停出问题的虚机镜像,来隔离它与其他系统及服务之间的逻辑联系,此举既不会破坏该虚机上的证据,又能够阻止事态的恶化。
总的说来,我们可以参考如下流程,来有效应对突发事件。
 编辑搜图
编辑搜图
结语
综上所述,我们从开发安全、系统梳理、权值分级、风险管理、以及监控响应五个方面,讨论了可落地的系统安全实践要点。
面对纷繁复杂的内外部网络环境,我们应当秉承着“害人之心不可有,防人之心不可无”的朴素概念,积极主动地对本企业的IT系统,持续进行抽丝剥茧式的梳理、检查与改进。我相信只要各个企业都能及时补齐安全短板,咱们国家的网络安全整体态势就会显著提高。
作者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
可优惠产品清单

一次合作 终生朋友

部分客户(无排名)










我有话说: