【高并发】在高并发环境下该如何构建应用级缓存?

 分类:
分类: 已被围观
已被围观 跟着我们的体系负载越来越高,体系的性能就会有所下降,此时,我们能够很自然地想到运用缓存来解决数据读写性能低下的问题。可是,立志成为资深架构师的你,是否能够在高并发环境下合理并且高效的构建运用级缓存呢?
缓存命中率
缓存命中率是从缓存中读取数据的次数与总读取次数的比率,命中率越高越好。缓存命中率=从缓存中读取次数 / (总读取次数 (从缓存中读取次数 + 从慢速设备上读取次数))。这是一个非常重要的监控目标,假如做缓存,则应通过监控这个目标来看缓存是否工作杰出。
缓存收回战略
1.根据空间
根据空间指缓存设置了存储空间,如设置为10MB,当达到存储空间上限时,依照必定的战略移除数据。
2.根据容量
根据容量指缓存设置了最大巨细,当缓存的条目超越最大巨细时,依照必定的战略移除旧数据。
3.根据时刻
TTL(Time To Live):存活期,即缓存数据从创立开始直到到期的一个时刻段(不管在这个时刻段内有没有被拜访,缓存数据都将过期)。
TTI(Time To Idle):空闲期,即缓存数据多久没被拜访后移除缓存的时刻。
4.根据目标引证
软引证:假如一个目标是软引证,则当JVM堆内存不足时,废物收回器能够收回这些目标。软引证适合用来做缓存,然后当JVM堆内存不足时,能够收回这些目标腾出一些空间供强引证目标运用,然后防止OOM。
弱引证:当废物收回器收回内存时,假如发现弱引证,则将它立即收回。相对于软引证,弱引证有更短的生命周期。
注意:只要在没有其他强引证目标引证弱引证/软引证目标时,废物收回时才收回该引证。即假如有一个目标(不是弱引证/软引证目标)引证了弱引证/软引证目标,那么废物收回时不会收回该弱引证/软引证目标。
5.收回算法
运用根据空间和根据容量的缓存会运用必定的战略移除旧数据,常见的如下。
- FIFO(First In First Out):先进先出算法,即先放入缓存的先被移除。
- LRU(Least Recently Used):最近最少运用算法,时刻时刻距离现在最久的那个被移除。
- LFU(Least Frequently Used):最不常用算法,必定时刻段内运用次数(频率)最少的那个被移除。
实践运用中根据LRU的缓存居多。
缓存类型
堆内存: 运用Java堆内存来存储目标。运用堆缓存的优点是没有序列化/反序列化,是最快的缓存。缺陷也很明显,当缓存的数据量很大时,GC(废物收回)暂停时刻会变长,存储容量受限于堆空间巨细。一般通过软引证/弱引证来存储缓存目标。即当堆内存不足时,能够强制收回这部分内存开释堆内存空间。一般运用堆缓存存储较热的数据。能够运用Guava Cache、Ehcache 3.x、 MapDB完成。
堆外内存: 即缓存数据存储在堆外内存,能够减少GC暂停时刻(堆目标转移到堆外,GC扫描和移动的目标变少了),能够支持更多的缓存空间(只受机器内存巨细限制,不受堆空间的影响)。可是,读取数据时需求序列化/反序列化。因此,会比堆缓存慢很多。能够运用Ehcache 3.x、 MapDB完成。
磁盘缓存: 即缓存数据存储在磁盘上,在JVM重启时数据还存在,而堆/堆外缓存数据会丢失,需求重新加载。能够运用Ehcache 3.x、MapDB完成。
分布式缓存: 分布式缓存能够运用ehcache-clustered(合作Terracotta server)完成Java进程间分布式缓存。也能够运用Memcached、Redis完成。
缓存模式
单机模式: 存储最热的数据到堆缓存,相对热的数据到堆外缓存,不热的数据到磁盘缓存。
集群模式: 存储最热的数据到堆缓存,相对热的数据到对外缓存,全量数据到分布式缓存。
写在最终
假如觉得文章对你有点帮助,请微信搜索并重视「 冰河技术 」微信公众号,跟冰河学习高并发编程技术。
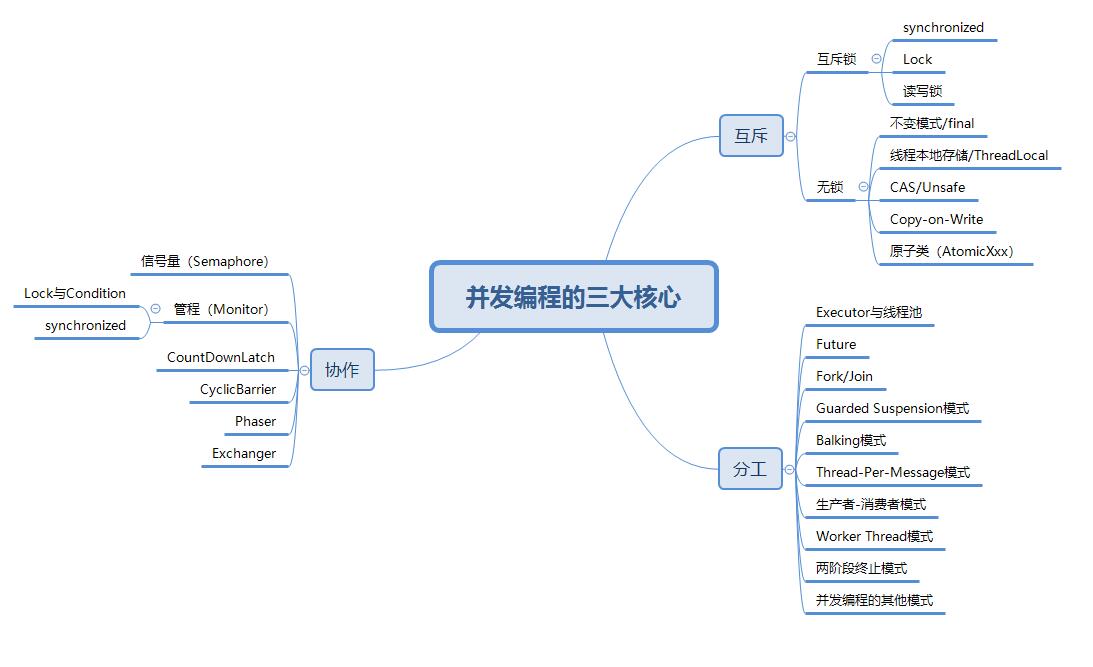
最终,附上并发编程需求掌握的中心技术知识图,祝我们在学习并发编程时,少走弯路。
可优惠产品清单

一次合作 终生朋友

部分客户(无排名)










我有话说: